How Likely Is It To Discover New CVEs in a Debian Package: A Rough Analysis
I am going to fuzz real-world programs to find out vulnerabilities. The first step is to find some “proper” targets, which are easy to expose bugs under fuzz testing.
Debian packages is a large collection of widely used programs. We will focus on programs included by Debian 11 “bullseye” distribution, and answer the questions below:
- How many packages have at least one associated CVE?
- How many CVEs does each package have on average?
You can check Analysis Results section for answers.
Data Preparation
One may consider making use of Debian DSA data to extract CVE IDs for every package, since DSA is CVE-Compatible. However, DSA does not cover all the CVEs related to Debian packages. In fact, only important security threats are captured by DSA.
We are going to collect package names, and find out CVE entries associated with each package.
Collecting Package Names
We can obtain Debian package names by a simple apt-cache command line:
# docker run --rm -it debian:11 /bin/bash
echo 'deb http://mirrors.hit.edu.cn/debian bullseye main' > /etc/apt/sources.list
apt update
apt-cache pkgnames > names.txt
We get 58,635 packages listed. As a reference, when Debian bullseye was released in August 2021, it contained 59,551 packages, including non-free and contrib packages. In this post we take only main packages into consideration, so 58,635 is a reasonable amount.
Many programs have occupied more than one package names. For example, Firefox is divided into 99 packages such as firefox-esr-l10n-zh-cn, firefox-esr-l10n-en-gb and so on. Another example is libexif, which is split into 6 parts: libexif-dev, libexif-doc, libexif-gtk5, libexif-gtk3-5, libexif-gtk-dev and libexif12.
It is obviously that we should regard these separated packages as one single unique program. I use a simple strategy to identify each unique program – take the first English word of each package name as its “unique” program id. In other words, a package name is truncated at the first non-alphabetical character.
Two examples are shown below:
$$\text{libtinyxml} \begin{cases} \text{libtinyxml-dev} \\ \text{libtinyxml-doc} \\ \text{libtinyxml2-8} \\ \text{libtinyxml2-dev} \\ \text{libtinyxml2.6.2v5} \\ \text{libtinyxml2.6.2v5-dbg} \\ \end{cases} \text{firefox} \begin{cases} \text{firefox-esr} \\ \text{firefox-esr-l10n-*} \\ \end{cases} $$
pdf2svg, it is incorrectly identified as a part of program pdf, which makes no sense. Since I have no better idea about how to reduce repetitive package names, I tolerated these infrequent mistakes.The reduction can be done with a short Python snippet.
import string, json
def get_program_name(s):
res = ''
for c in s:
if c in string.ascii_letters:
res = res + c
else:
break
# package name `2to3` will not be reduced
return res or s
names = [x.strip() for x in open('names.txt').readlines()]
json.dump(sorted(list(set(map(get_program_name, names)))), open('reduced.json', 'w'))
We find that programs which occupied most package names are: python(4377 packages), libghc(3135), golang(1548), librust(1440), ruby(1383), node(1383), r(1139), php(526), etc. The top-100 word cloud is illustrated here:

After reduction, we have 14,765 unique programs, which indicates that each unique program is separated into 3.97 Debian packages on average.
Collecting CVE Entries
CVE list is available on cve.mitre.org. Each CVE entry contains a CVE-ID, a description and some references. One can search the CVE list by keywords.
We will utilize reduced program names as keywords to search the CVE list and match CVE records with programs; that is, if a program name is contained by the description field of a CVE, we connect the program with that CVE entry. This method works just like searching by a program name manually.
CVE list is a big table with over 200,000 entries, which means that if we perform brute-force search for every program (there are 14,765 of them), the total time complexity would be unacceptable.
Algorithms such as Aho–Corasick Automaton could bring significant improvements; however, I am too lazy to implement them. I decided to make utilize of RDBMS for text searching. With the help of the powerful PostgreSQL, we can easily perform efficient searches.
postgres=# CREATE DATABASE cve;
-- CREATE DATABASE
postgres=# \c cve
-- You are now connected to database "cve" as user "postgres".
cve=# CREATE TABLE cve (Name TEXT, Status TEXT, Description TEXT, Refer TEXT, Phase TEXT, Votes TEXT, Comments TEXT);
-- CREATE TABLE
cve=# \copy cve FROM 'cve2.csv' DELIMITER ',' CSV HEADER
-- COPY 253336
cve=# SELECT name FROM cve WHERE description ~* '\mteeworlds';
-- name
-- ----------------
-- CVE-2014-9351
-- CVE-2016-9400
-- CVE-2018-18541
-- CVE-2019-10877
-- CVE-2019-10878
-- CVE-2019-10879
-- CVE-2019-20787
-- CVE-2020-12066
-- CVE-2021-43518
-- (9 rows)
We use ~* instead of ~ to carry out a case-insensitive regex search, and use \m to match program name only at the beginning of words.
The searching speed (about 4 program names per second on my PostgreSQL instance) is still not fast enough for us. So we create an index to speed up the query:
cve=# create extension pg_trgm;
-- CREATE EXTENSION
cve=# create index on cve using gin (Description gin_trgm_ops);
-- CREATE INDEX
cve=# EXPLAIN SELECT name FROM cve WHERE description ~* '\mteeworlds';
-- QUERY PLAN
-- ------------------------------
-- Bitmap Heap Scan on cve (cost=96.15..170.63 rows=19 width=14)
-- Recheck Cond: (description ~* '\mteeworlds'::text)
-- -> Bitmap Index Scan on cve_description_idx (cost=0.00..96.14 rows=19 width=0)
-- Index Cond: (description ~* '\mteeworlds'::text)
Now we can execute 105.45 queries per second. The full script to extract related CVEs for each package is as follows:
import psycopg2, json
from tqdm import tqdm
names = json.load(open('reduced.json', encoding='utf8'))
# print(names)
conn = psycopg2.connect(
database="cve",
user="postgres",
password="***", host="***", port=5432)
cve_map = {}
for program in tqdm(names):
with conn.cursor() as cursor:
cursor.execute("SELECT name FROM cve WHERE description ~* CONCAT('\m', %s)", (program, ))
res = cursor.fetchall()
cve_map[program] = [x[0] for x in res]
json.dump(cve_map, open('cve_map.json', 'w', encoding='utf8'))
Case Study
Now for each package, we have its associated CVE records in database. I inspected some interesting programs as below.
Chrome
As the world’s most popular browser, Chrome has been widely tested by researchers and hackers. We collected 3200 CVEs in Chrome, while Mitre CVE Search reports 3226 related CVEs.
CVE-2001-1410 is marked as belonging to Chrome by our analyzer, for its description includes “… to create chromeless windows …”, so this record is a false positive case.
Libexif, Libtiff, Libpng, GIMP
I have fuzzed several photo processing libraries, it is often easy to detect vulnerabilities in them by fuzzing.
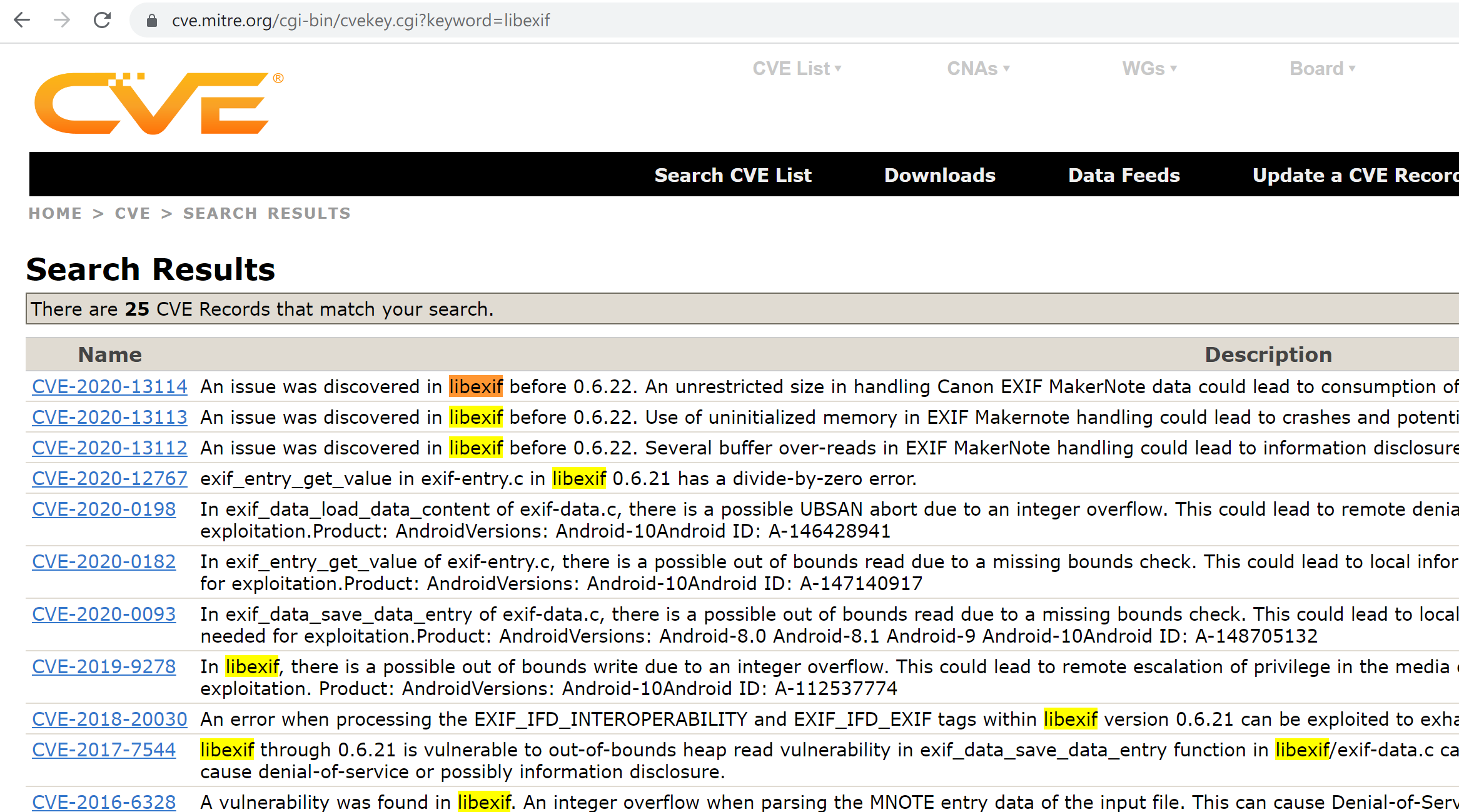
Libexif has 21 related CVEs: CVE-2005-0664, CVE-2006-4168, CVE-2007-2645, CVE-2007-6351, CVE-2007-6352, CVE-2009-3895, CVE-2012-2812, CVE-2012-2813, CVE-2012-2814, CVE-2012-2836, CVE-2012-2837, CVE-2012-2840, CVE-2012-2841, CVE-2016-6328, CVE-2017-7544, CVE-2018-20030 , CVE-2019-9278, CVE-2020-12767, CVE-2020-13112, CVE-2020-13113, CVE-2020-13114.
Libtiff has 230 CVEs, libpng has 66 CVEs.
GIMP has 44 related CVEs reported by our analyzer. The latest record, CVE-2022-32990 is discovered by AFL.
Analysis Results
How many programs have related CVE?
4661/14765 (31.57%) of programs in Debian 11 “bullseye” have related CVEs.
How many libraries have related CVE?
573/4959 (11.55%) of lib* packages have related CVEs.
How many CVEs does each program have on average?
Some program names are connected with ≥ 10,000 CVEs. For example, the package name an is contained by 195,281 CVE descriptions. We have to remove these data to prevent large bias in the analysis results.
We take a program into consideration if it meets the following two requirements:
- Length of name is greater than 5.
- Related CVEs is less than 500.
We call these programs “regular programs”. There are 10,957 regular programs in Debian Package, and 2,206 (20.13%) of them have CVEs. The amount of CVEs associated with them is 40,980.
On average, each regular program has 3.74 CVEs. Please note that this is a very rough result.
Additionally, we have an interesting finding: if a regular program has at least one related CVE, there is a 67.72% probability that it has multiple CVEs. This result suggests that it might be easier for us to find vulnerabilities in packages that already have related CVE records.